Getting Started with AWS and Terraform: 02 - Hosting a dockerized web service in our EC2 container
Hello again! Welcome back to our multi-part blog series on getting started with AWS and Terraform.
In part two of this series, we’ll take our humble EC2 instance, deploy a web server image to it, and make it reachable from anywhere across the internet.
At the end of this post you should be able to:
- Configure an Elastic Container Repository (ECR)
- Deploy a Docker Image to ECR
- Pull and run Docker Images from ECR onto an EC2 instance
Prerequisites
- Completed the steps from part 1
- The steps in this post follow directly from where we left off in the last post
- Installed awscli
- We’ll be using the awscli locally to provide credentials to Docker to interact with AWS ECR
- Installed Docker Desktop (or at least the Docker Engine)
- We’ll be using Docker to build a simple node application into a Docker image and push the image to AWS ECR
Step 1 - Create an ECR Repository
In this step we’ll define our ECR repository which will store our web server container images.
AWS ECR is a service for hosting container image repositories which can be used by services on the internet to pull and run container images.
As we may be applying and destroying our environment multiple times, it might be simpler to create this repository in another Terraform project.
Create a new directory alongside infra called ecr.
Add a main.tf and aws-provider.tf as shown in this gist, replacing the aws provider keys and region with your own then run terraform init.
Create a new file called ecr.tf within the ecr directory and add the following:
# /ecr/ecr.tf
resource "aws_ecr_repository" "unicorn_api_ecr" {
name = "unicorn-api"
image_tag_mutability = "MUTABLE"
image_scanning_configuration {
scan_on_push = true
}
}
output "unicorn_api_ecr_uri" {
description = "The uri of the unicorn api ecr repository"
value = aws_ecr_repository.unicorn_api_ecr.repository_url
}
Above we have defined a new aws_ecr_repository resource and an output value of the repo uri which will be used to push and pull our container image.
The image_tag_mutability property controls whether tags can be reused.
When set to MUTABLE, tags can be reused, allowing clients to pull the latest image automatically (e.g. via the latest tag).
When set to IMMUTABLE tags are fixed to specific images which prevents automatic updates but provides clients with greater stability and control as the image wont change unless the tag itself is updated.
There are many risks associated with tag mutability.
- An attacker could replace a trusted image with a malicious one
- An image could change during a deployment pipeline, tests could run against one image but the deployed image could be different. This is also known as a Time-of-Check to Time-of-Use (TOCTOU) issue
- Additionally, there can be ambiguity with which image version is in production, which can make debugging issues tricky
Tag immutability helps to mitigate these issues:
- Once a tag has been associated to an image, it will always refer to the same image
- Deployed image versions can be more easily traced by referencing their tags
- Deployments are more stable. The image tag used for tests in pre-production reference the same image being deployed to production
For the purposes of this exercise, we will set tag mutability to MUTABLE if only so we won’t need to update multiple scripts each time we want to change our web server. In general though, it is recommended to use immutable tags for a more reliable, and secure service.
The scan_on_push property controls whether images should be scanned for vulnerabilities upon being pushed to the repository. As it’s free to enable, we might as well do so in case it finds any CVEs.
The name property should be self-evident.
Let’s run terraform apply to create this repository, and make note of the repository uri output.
Step 2 - Building our web server image and pushing it to ECR
Now that we’ve defined an ECR repo, we need a container image to host within the repo. This image could be whatever we want it to be, but in our case, let’s make it a simple node web api.
Here’s one I prepared earlier! Clone this repo and then navigate to the directory.
Create a new bash script named build-and-push.sh and add the following:
#!/bin/bash
aws --profile [your-aws-cli-profile] ecr get-login-password --region [region] | sudo docker login --username AWS --password-stdin [ecr-uri]
sudo docker build -t unicorn-api .
sudo docker tag unicorn-api:latest [ecr-uri]:latest
sudo docker push [ecr-uri]:latest
aws --profile [your-aws-cli-profile] ecr list-images --repository-name unicorn-api
We’ll also need to enable read/write/execute permissions on the script in order to run it.
chmod 700 build-and-push.sh
Now run the script and if all went well you should see the following output:
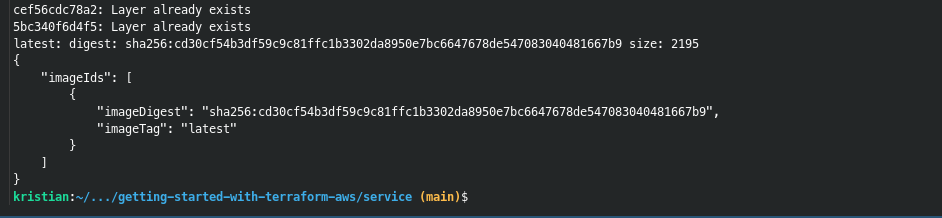
Step 3 - Pull the ECR image onto EC2 instance and run it
By now we should have an EC2 instance running in AWS and a container image hosted on ECR. Now we just need to run the image on our EC2 instance.
In order to achieve this we’ll need to:
- Add a security egress rule to allow EC2 to connect to ECR
- Define a role to allow read access to ECR and assign it to our EC2 instance
- write another custom script to run on our instance which will pull the docker image and run it in its own Docker environment
Lets define our security group rule first.
Open the unicorn-api.tf file and add the following egress rule:
# /infra/unicorn-api.tf
resource "aws_vpc_security_group_egress_rule" "allow_outgoing_https" {
security_group_id = aws_security_group.unicorn_api_security_group.id
description = "allow egress via port 443"
cidr_ipv4 = "0.0.0.0/0"
ip_protocol = "tcp"
from_port = 443
to_port = 443
}
This security group egress rule allows our EC2 instance to make https requests over the internet. ECR operates over HTTPS which is why declare TCP and ports 443.
You can validate that this changed worked by sshing into you EC2 instance and connecting to a website over https, e.g. curl https://www.google.com.
Note: We’re allowing egress over HTTPS to any node on the internet when we only need to connect to ECR. As we learned in the previous blog post this violates the principle of least privilege. There is an alternative to this, which is to create a VPC Endpoint for connecting to the ECR Service and allowing egress to that endpoint but that is beyond the scope of this blog post.
Now that we can connect to ECR, we need to provide access for our EC2 instance to run commands against ECR.
In your infra directory create a new file iam.tf and add the following:
# /infra/iam.tf
resource "aws_iam_role" "ec2_ecr_readonly_role" {
name = "ec2-ecr-role"
assume_role_policy = data.aws_iam_policy_document.ec2_assume_role_policy.json
inline_policy {
name = "ecr-read-policy"
policy = data.aws_iam_policy_document.ec2_container_registry_read_only.json
}
}
data "aws_iam_policy_document" "ec2_assume_role_policy" {
statement {
actions = ["sts:AssumeRole"]
principals {
type = "Service"
identifiers = ["ec2.amazonaws.com"]
}
}
}
data "aws_iam_policy_document" "ec2_container_registry_read_only" {
statement {
actions = [
"ecr:GetAuthorizationToken",
"ecr:BatchGetImage",
"ecr:GetDownloadUrlForLayer",
]
resources = ["*"]
}
}
What we have done is defined an aws_iam_role and applied a couple of aws_iam_policy_documents which:
- Define which services can assume this role (
ec2_assume_role_policy). In this case only the EC2 service can assume the role - Define the actions a service with role can perform (
ec2_container_registry_read_only).
Our EC2 service requires three actions:
- one to allow the principal to authenticate with ECR
- one to query the manifest of a container image pulled from ECR
- one to query the download URLs of the the container image layers
We’ve defined our role and appropriate policies for the role, now we need to apply it to our EC2 instance.
Open unicorn-api.tf and add the following resource:
# /infra/unicorn-api.tf
resource "aws_iam_instance_profile" "unicorn_api_iam_profile" {
name = "unicorn-api-iam-profile"
role = aws_iam_role.ec2_readonly_role.name
}
Now add the iam instance profile to the aws instance.
# /infra/unicorn-api.tf
resource "aws_instance" "unicorn_api" {
# ...
iam_instance_profile = aws_iam_instance_profile.unicorn_api_iam_profile.name
# ...
}
Great! Now that we’ve defined the IAM role and applied it to our EC2 resource, we can define a script for our instance to run on start up which will pull the ECR image and run it in docker.
Create a new file in the infra directory, init-unicorn-api.sh
#!/bin/bash
aws ecr get-login-password --region [region] | docker login --username AWS --password-stdin [ecr repository url]
docker run -p 80:8080 [ecr repository url]:latest
Add the script to the EC2 instance user data property:
#! /infra/unicorn-api.tf
resource "aws_iam_instance_profile" "unicorn_api_iam_profile" {
# ...
user_data = file("${path.module}/init-unicorn-api.sh")
# ...
}
With all that setup, we should now have an EC2 instance running a simple web server listening on port 80. There’s just one final step to allow this service to be reachable from any device on the internet.
Step 4 - Allow any device on the internet to connect to our web server
So far we’ve created a web service Docker image, pushed the image to ECR, and pulled & run the image on our EC2 instance.
Now we need to revisit our security group rules and update our ingress rule to allow incoming connections from any IP over port 80. Remove your existing ingress rule and replace it with the following.
# /infra/unicorn-api.tf
resource "aws_vpc_security_group_ingress_rule" "allow_incoming_http" {
security_group_id = aws_security_group.unicorn_api_security_group.id
description = "allow ingress via port 80"
cidr_ipv4 = "0.0.0.0/0"
ip_protocol = "tcp"
from_port = 80
to_port = 80
}
With all of that we can run terraform apply to apply our changes.
Copy the EC2 public domain name output into a browser (you may need to prepend http:// to the address as your browser might assume to use https) and see your awesome website!
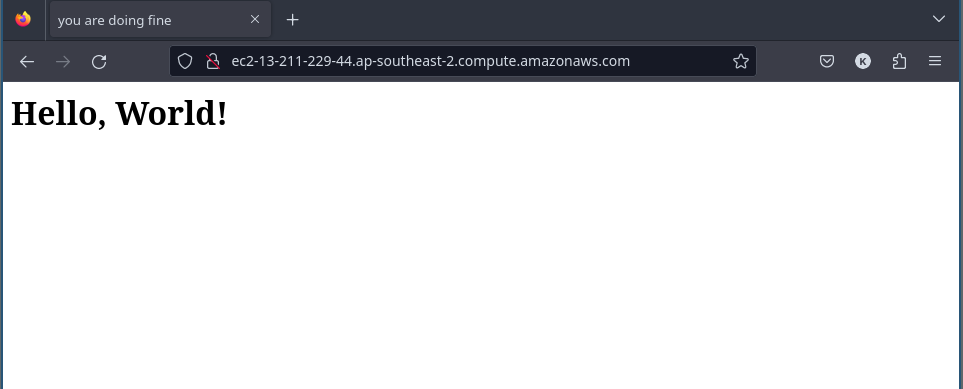
Great! We’ve deployed a Hello World! web site to AWS!
Our domain name kinda sucks though, not to mention it will change every time we deploy changes, which isn’t ideal for keeping people coming back to our website.
In the next post we’ll look at how to configure a domain name for our web site so we no longer have to rely on our EC2 domain name.
See here to get the final code output from this post.